AI, ML, and Large Language Models
2023
I often describe myself as a generalist software engineer with a broad range of experience in web app development, system development, front end, back end, devops, etc, but I must confess I have a somewhat blind spot when it comes to data science.
In the past, I’ve worked with machine learning at Eagleview, constructed analytic dashboards at LiquidPlanner, and tackled an array of random business queries with hastily assembled SQL, R, or Excel at different points in my career. However, the recent surge in AI interest has left me feeling somewhat like I’m missing out.
Therefore, I’ve been dedicating some time to getting back up to speed with machine learning and - unsurprisingly given the current hype - with large language models and natural language processing. You can find some of my thoughts on the subject below…
Artificial Intelligence
The term AI covers a wide range of topics:
- Natural Language Processing
- Computer Vision
- Robotics
- Expert Systems
- Self Driving Cars
- Generative AI
- AGI - Artificial General Intelligence
When applied correctly, AI techniques can help solve or enhance a variety of business problems across numerous domains. From a software engineering perspective, our primary concerns are:
-
Machine Learning - the ability to train a model to learn from data and make predictions or decisions without the need for explicitly structured programming
-
Deep Learning - a subset of machine learning that utilizes neural networks with “deep” layers, enabling more complex learning
-
Large Language Models - a subset of deep learning trained with a substantial corpus of natural language content, that develops a robust semantic understanding of language structure. This can be used to accomplish numerous text-related tasks, even when not explicitly trained for those tasks
Traditional Machine Learning
Traditional machine learning algorithms have been successfully used for decades. These algorithms perform well, boasting robust implementations in machine learning libraries like scikit-learn. They should probably remain the go-to solutions for many problems, especially when dealing with structured tabular data, where decision trees (and ensemble techniques like random forests or gradient boosting) continue to prove more accurate than deep learning techniques.
- Linear Regression - predicts real values (e.g. house prices)
- Logistic Regression - classifies discrete values (e.g. yes/no, cat/dog/rabbit)
- Decision Trees - used for both classification and regression
- Random Forests - an ensemble of simpler decision tree models
- Gradient Boosting - another ensemble technique
- Naive Bayes - probability classification using Bayes theorem (e.g. spam detection)
- K Nearest Neighbours - solve regression or classification problems using locality
- Collaborative Filtering - used for recommendation systems
Deep Learning and Neural Networks
… but in the last decade or so, deep learning has taken center stage, using neural networks that can decipher complex non-linear relationships given sufficient parameters and training data. A neural network is considered a universal function approximator - signifying that it can be trained to approximate the result of any function.
A neural network can be defined by:
- architecture - the selection and arrangement of the network layers
- parameters - the trained weights used at inference time
- hyperparameters - the parameters employed during training (e.g. learning rate)
There exists a variety of neural network architectures, each designed to handle specific tasks in the field of artificial intelligence:
- Feed-forward neural networks (FFNN) - the traditional densely layered network
- Convolution neural networks (CNN) - primarily used for image processing
- Recurrent neural networks (RNN) - ideal for text and time series data
- Long short-term memory networks (LSTM) - suitable for tasks involving long sequences
- Generative adversarial networks (GAN) - capable of augmenting and generating content
The Transformer Architecture
A 2017 Google paper - Attention is all you need introduced a novel type of neural network architecture known as the transformer.
This was designed to excel at text transformation tasks, such as language translation, and could be trained on a large corpus of text using unsupervised (e.g. unlabelled) training techniques like masking words and training the model to predict the missing word.
Its proficiency in text transformation enables it to easily:
- transform language
- modify tone
- adjust personality
- alter structure
- correct grammar and spelling
In addition to text transformation the transformer architecture also excels at:
- text summarization - summarizing the semantic meaning
- text completion - filling in a missing word or completing a sentence
- text classification - identifying the subject, language, etc
- sentiment analysis - determine the positive/negative sentiment
- entity recognition - extracting nouns (e.g. people and place names)
- action recognition - identify verbs (actions)
Surprisingly, a language model employing the transformer architecture, when provided with sufficient training data and configured with a large number of parameters, begins to exhibit emergent behaviour that can appear intelligent.
-
Information retrieval - with the right input (prompt), a language model can answer questions about its training data, or about the content provided in the prompt.
-
Chain of thought reasoning - again with carefully structured input, a language model can be guided to break down a task and use multiple steps to arrive at an answer.
-
Autonomous agency - with careful prompting, a language model can transform natural language tasks into programmatic actions that can be used to query or invoke external resources.
This marked the advent of the Large Language Model, and - perhaps - some of the first real signs of emerging artificial intelligence…
AutoComplete vs AGI
… However, it’s crucial to understand that a large language model is - at its heart - a predictive text model that:
- is trained with a large corpus of natural language text
- learns a semantic understanding of language
- understands the relationships between words
- … and becomes EXCEPTIONALLY GOOD AT PREDICTING THE NEXT WORD
Yes, an LLM can provide many useful abilities that, I believe, can significantly improve our applications and their user experience for the better. And yes, an LLM can exhibit some emergent behaviors that appear intelligent if trained or prompted under controlled circumstances. However, an LLM on its own:
- … does not think
- … does not reason
- … does not reflect
- … does not interact with the world
- … does not learn (beyond its training)
- … is not conscious
- … is very, very, far from AGI (artificial general intelligence)
… but these models certainly are a powerful tool to add to our software development toolbelt.
The LLM Landscape
Let’s explore the current large language model landscape with the help of a survey of large language models. The diagram below demonstrates the evolution of OpenAI’s GPT models, culminating in the recent release of GPT-4, which is available in ChatGPT, BingAI, and the Open AI platform.
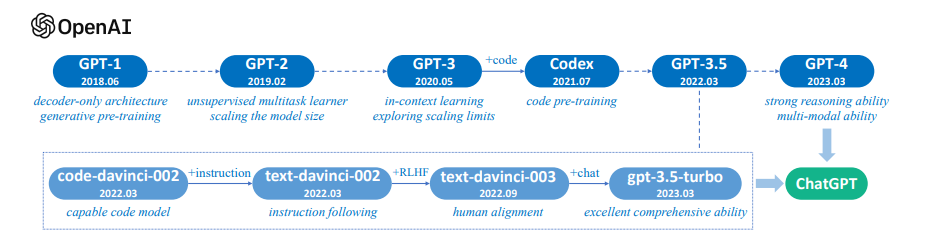
However, GPT is not the only game in town. This diagram, also derived from a survey of large language models, was published merely a month ago (at the time of writing) and is already outdated due to last week’s release of Meta’s Llama 2 and Stability AI’s Free Willy 2.
The diagram illustrates the evolutionary paths of various large models from prominent companies in recent years. Given the excitement in the field, new models are being released continuously.
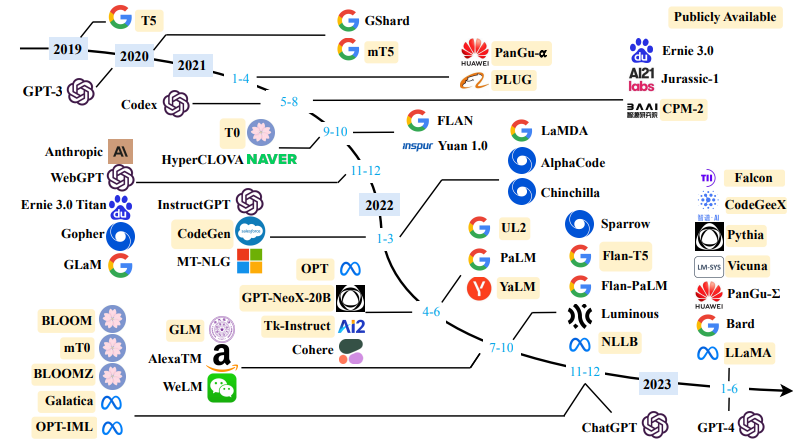
Some models are commercial, while others are open source. However it’s necessary to carefully review each model’s license to ascertain whether it can be utilized for your tasks.
| Commercial | Open | |||
|---|---|---|---|---|
| GPT | (Open AI) | LLAMA 2 | (Meta) | |
| CLAUDE | (Anthropic) | ALPACA | (Stanford) | |
| PALM/BARD | (Google) | MPT | (Mosaic ML) | |
| GPT/BING | (Microsoft) | FREE WILLY 2 | (Stability AI) | |
| COLPILOT | (GitHub) | OPEN LLAMA | (Berkeley) | |
| BLOOM | (Big Science) | |||
| BERT | (Google) | |||
| T5 and FLAN-T5 | (Google) |
The latest advancements on the commercial side are GPT-4 and Claude, while on the open-source side, the recent releases of Llama2, Free Willy 2, and MPT are generating excitement. This information will likely be outdated by the time you read this article :-)
There are numerous models being published every week…
huggingface.co is a tech company that originally provided the open-source transformer library for building transformer networks in Python. Now it hosts many open models, provides open datasets, and is evolving into a community for open-source LLM knowledge sharing and tools. They offer a portal to search for models as well as a leader board tracking the performance of various metrics across the most popular models.
Prompt Engineering
NOTE: The prompt examples in this section come from the exceptional online course Generative AI with Large Language Models from Andrew Ng’s deeplearning.ai
If you are reading this article (thank you) - you have likely used ChatGPT and already have a good understanding of what it means to prompt a language model. The most fundamental prompt often comes directly from a user. The prompt is sent to the model, and the LLM attempts to COMPLETE THE TEXT WITH THE MOST PROBABLE SUBSEQUENT WORDS. Thus, it’s crucial to understand that the LLM isn’t exactly “answering the question” as we might perceive it. Instead, it uses the knowledge it acquired from its training data to predict the set of words that best completes the response.
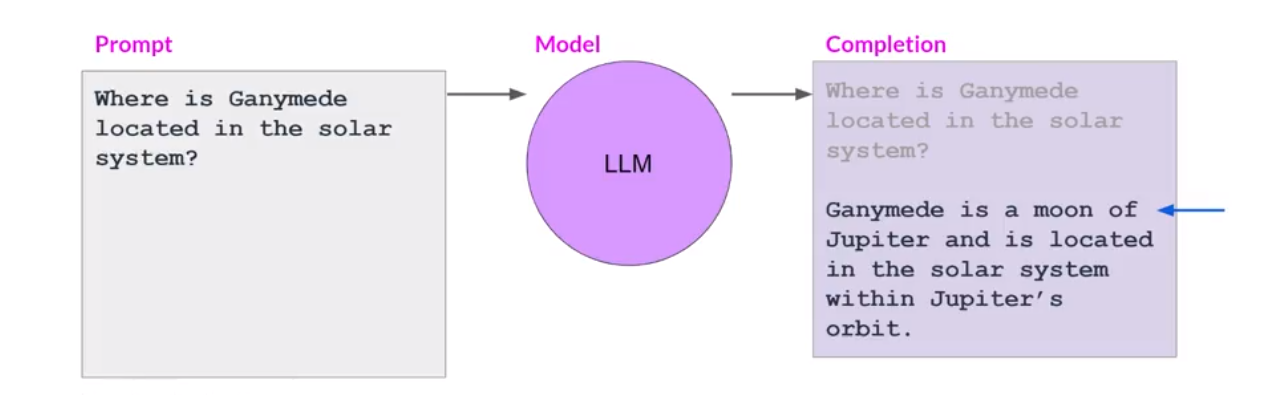
Without structure, a simple prompt coming directly from a user can cause an LLM to face some serious challenges:
- they don’t have access to facts that occurred after their training date
- they don’t have a real model of the world, so they are often incorrect
- they are frequently prone to hallucinations
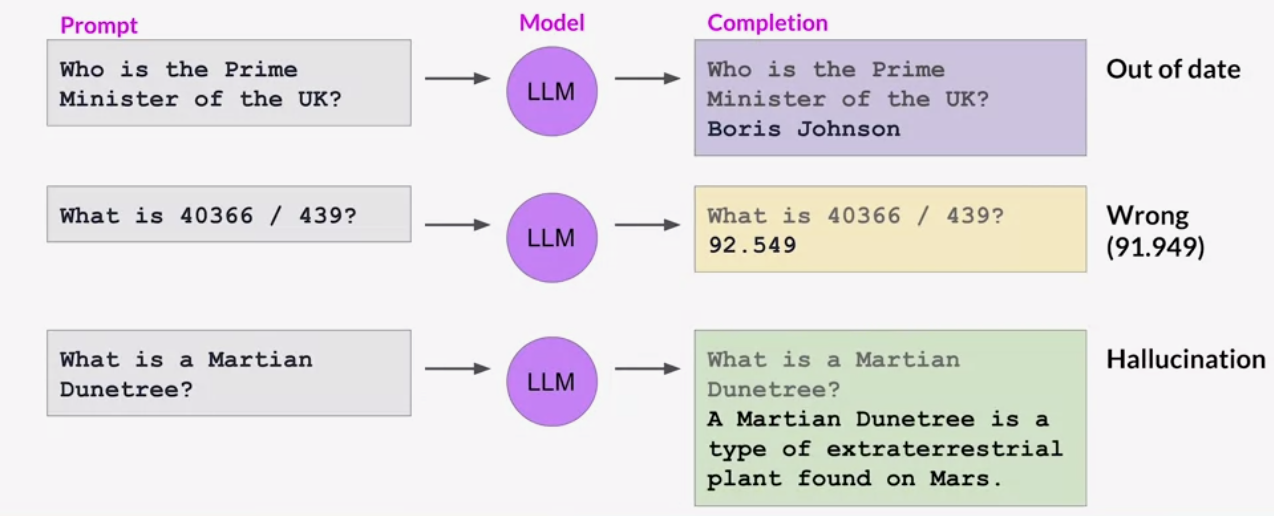
To mitigate these issues, we employ a process called prompt engineering.
Being a predictive text model, an LLM responds effectively if the question or instruction aligns with its training data. Prompt engineering is the art of structuring the prompt to guide the model to perform the desired task. In the example below, we provide an instruction to “Classify this review” accompanied by a hint that the text should be followed by the sentiment, but we do not include any examples. This is called zero-shot inference:
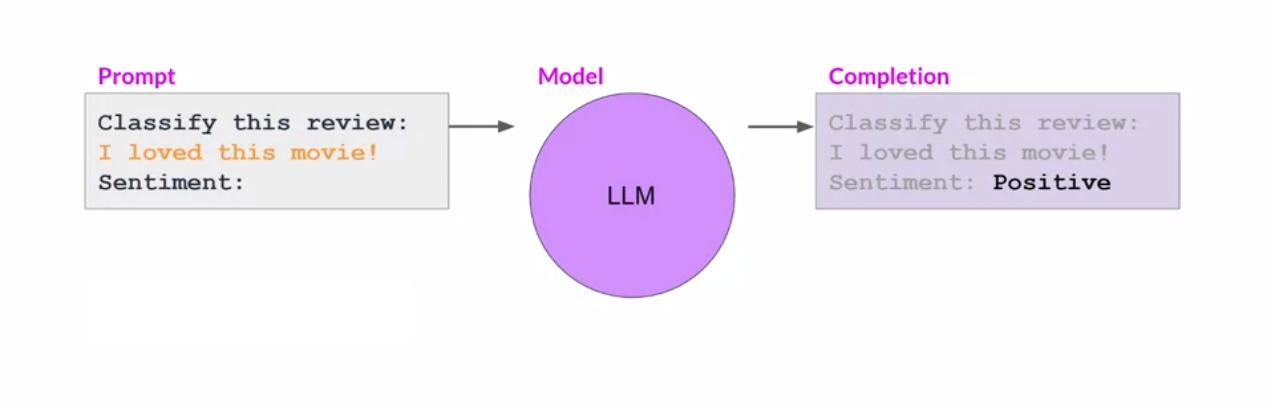
If the model struggles to perform the task, we can enhance the prompt to include a single example. This is called one-shot inference:
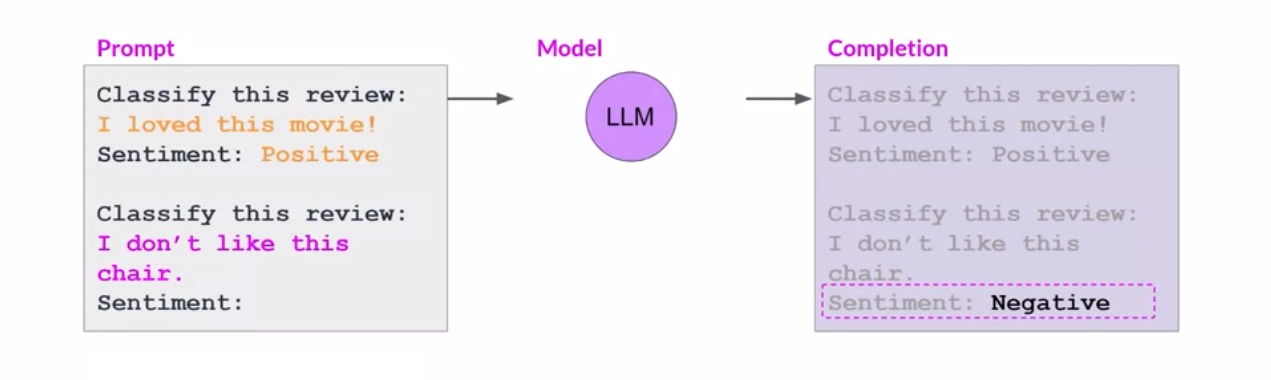
If the model continues to struggle, we can improve the prompt to include multiple examples. In the example below we include both a positive and a negative example to guide the model towards performing the task we desire, in this case sentiment analysis. This is called few-shot inference:

In more complex cases, for example (below), if we are using the LLM to perform math or draw a conclusion, our one-shot example can include a breakdown of the steps required to reach the answer. In this case our example explains why the answer is 11.
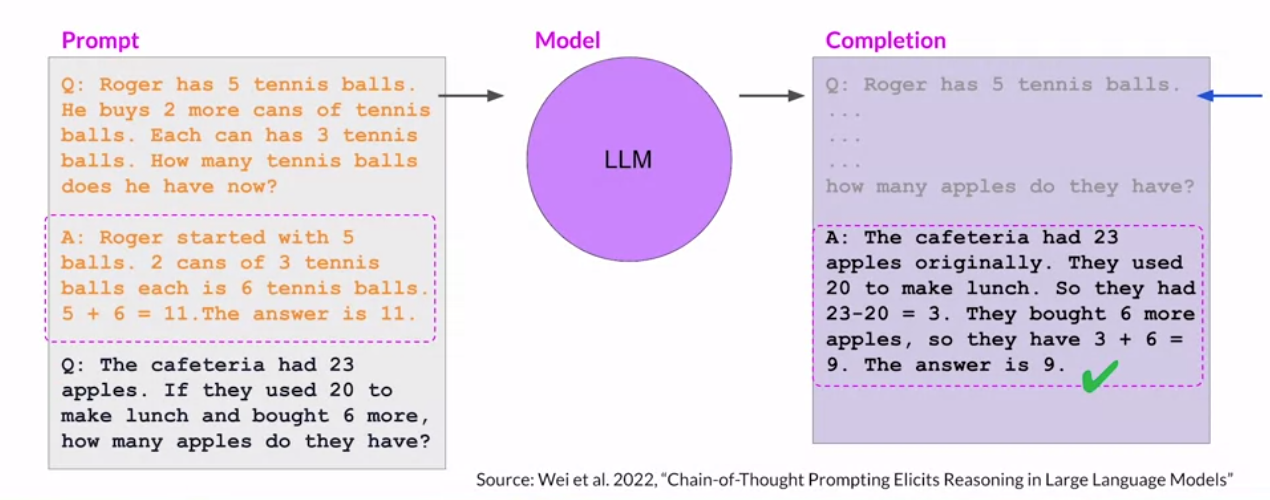
Again, it’s crucial to understand that the LLM is not making any mathematical calculations here. Our one shot example is broken down into smaller steps which guides our model to respond with a similar structure and break its own task down into smaller steps. Simpler steps equate to easier math, and easier math is much more likely to be guessed correctly by the model.
So there are various techniques, suggestions, and patterns that you can use to structure the prompt to guide the model to perform the desired task, including:
- use clear and specific instructions
- use delimiters to indicate distinct sections
- include examples of the desired task and its outcome
- specify the steps required to complete a task
- instruct the model to derive intermediate steps
- instruct the model to focus on key aspects
- instruct the model to evaluate its own answer and improve it
- instruct the model to constrain the output length
- instruct the model to provide structured output
In all honesty, this feels a lot like early SEO (search engine optimization), where various patterns emerged to try to rank at the top of the Google search results page. Some of the patterns were based on the underlying algorithm, while others were a bit more speculative - YMMV.
LLM Memory (or lack thereof)
One complication of working with large language models is that they possess no real ability to retain information. They do not learn from their tasks (ChatGPT has to include the recent conversation for context), they only have general knowledge up to their training cut-off date, and they have a limited context window (prompt) size for assimilating new knowledge.
- Can the model summarize “War and Peace” - YES
- it was part of the training data
- Can the model summarize the new Stephen King novel - NO
- it has no existing knowledge of it
- and it doesn’t fit into the context window
For simple tasks, the solution to this problem might involve breaking the task down into sub-tasks. So for this example we could ask the model to summarize each chapter (or whatever portion fits into the context window) and then ask the model to summarize the summaries.
However, more complex tasks necessitate other strategies…
RAG - Retrieval Augmented Generation
One approach to handling the context window limitation involves storing our company documents in a vector database that can be used to perform a semantic search for the documents related to the user’s question.
- The user asks a natural language question
- A semantic search is performed, returning related documents
- The LLM is provided with the original question plus the related documents
- A natural language answer is returned to the user
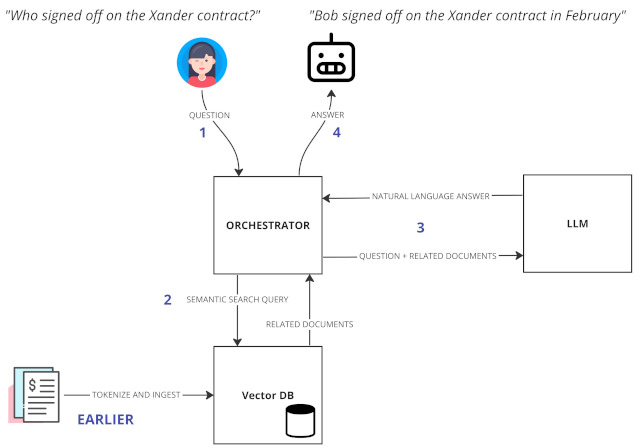
In this way, we only send a small, relevant subset of our full documentation that is compact enough to fit into the model’s context window.
PAL - Program Aided Language Model
A different, and potentially more powerful pattern, involves augmenting the LLM with an external orchestrator that can perform actions on its behalf.
- The user asks a natural language question
- The LLM transforms the question into an action (or query)
- The action is performed by the orchestrator
- The LLM transforms the results into a natural language answer
- The natural language answer is returned to the user
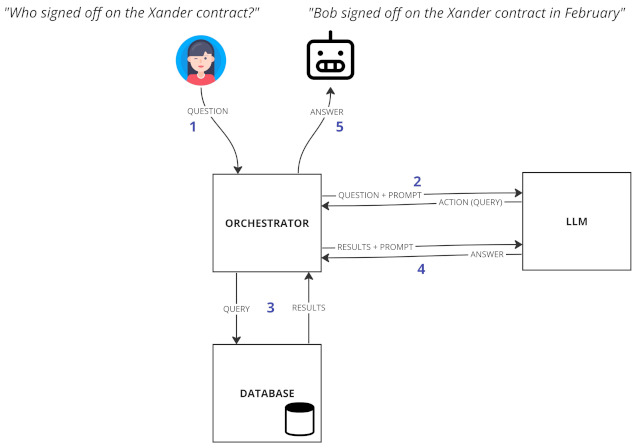
In this way, we are only using the LLM as a text transformation engine, transforming the user’s natural language request into actions that our application can perform - such as calling a function, querying a database, or making an API request - and then transforming our application’s responses back into natural language. I believe this could be a very powerful orchestration pattern, avoiding many of the complexities of working with an LLM.
Training a Model
Many of the prompt engineering and RAG patterns are workarounds for the fact that:
- the LLM has no knowledge of our specific facts
- the LLM context window is too small to teach it everything
A more robust solution is to train your own model, but that can be expensive and time consuming. Alternatively, you can fine tune a pre-trained model. This is much more efficient, and there are various mechanisms for undertaking fine tuning:
- Full instruction fine tuning
- Parameter efficient fine tuning (PEFT)
- Reinforcement learning from human feedback (RLHF)
Once you start down the path of training (or fine tuning) your own model, you will need a robust way to measure the performance - e.g. accuracy - of your model output. There are a number of different metrics, each designed to measure accuracy for different tasks:
- ROUGE - assess the quality of text summaries
- BLEU - asses the quality of text translations
- GLUE and SUPERGLUE - benchmarks for common tasks
- BIG BENCH and HELM - additional benchmarks for common tasks
- MMLU - benchmarks for standardized tests (SAT, law, math, etc)
Technical Challenges
Large language models are not a silver bullet. There are a number of technical challenges, not least of which is the cost to train and host the model.
- cost - the compute budget to train and run models can be prohibitive
- accuracy - ensuring accurate output requires investment
- alignment - ensuring output is helpful, honest, harmless requires investment
- speed - inference speed can be slow
- recent knowledge - post-training general knowledge is unavailable
- private knowledge - private facts are unavailable and must be taught
- limited context window - ability to include private facts is limited by size
- no in-built reasoning - careful prompt engineering must be performed
- no in-built autonomy - workflow orchestration must be built
However, given the growing interest and availability of open source models, experiments, prototypes, and concepts can be explored fairly quickly and easily.
Random Ideas
Using language models to provide a natural language user experience (UX) is a very different approach to building applications than traditional forms and rules-based UX. However, now that we have a tool that allows us to understand the semantic meaning behind natural language, you can easily start to imagine new ways of providing values, and new feature and product ideas…
- Consumer Reports - “Show me the top 3 fridges? must be quiet and energy efficient”
- Patents - “Find me existing patents that involve the development of super conductors…”
- Analytics - “Give me the top 10 sales, week over week, for the last 12 months…”
- Contracts - “What does this contract mean to me?”, “Which sections should I worry about?”
- Resumes - “Tell me more about Jake’s experience with Rust?”
Development Technologies
There are a lot of technologies that enable this eco-system. At the top of the chain is the Open AI platform. Their API and cookbook are driving a lot of innovation. Fast.ai provides a very valuable training course and a high level library for experimentation. Hugging Face is becoming THE hub for the open-source deep learning community, hosting models, datasets and more. Langchain is the latest exciting agent/orchestrator library of the moment, but the underlying python library eco system is vast with fundamentals provided by numpy, pandas, matplotlib, tensorflow, pytorch, keras, and scikit. However, python is not the only language embracing ML. ELixir has a growing machine learning community with Nx, Scholar, Axon, and Bumblebee…
- Open AI Platform
- Open AI Cookbook
- Fast AI library
- Hugging Face Models, Datasets, Transformers, and Tasks
- LangChain - the most recent cool kid on the block for LLM workflow chains
- Scikit-Learn, PyTorch, TensorFlow, Keras, Numpy and Pandas - python ML libraries
- Nx, Scholar, Axon, Bumblebee, - elixir ML libraries
- Jupyter labs - interactive python notebooks
- Livebook - interactive elixir notebooks
- Sagemaker - AWS build/train/deploy ML
- ChromaDB - open source vector database
- LLama Index - open source data and LLM framework
- Llama.cpp - run LLama on local machine
- Awesome-LLM - lists more tools
- Awesome-Public-Datasets/NLP - public NLP datasets
Training Courses
There are many ML training courses available for free. I found the short courses from deeplearning.ai to be excellent starting points, and their more in-depth “Generative AI with LLMs” course delves into further detail. The “Practical Deep Learning” course from fast.ai is outstanding but requires a longer time commitment as it is lengthy and detailed.
- DeepLearning.AI - Generative AI with LLMs (longer course on coursera)
- DeepLearning.AI - Building with ChatGPT API (short course)
- DeepLearning.AI - ChatGPT Prompt Engineering (short course)
- DeepLearning.AI - LangChain chat with Data (short course)
- Fast.AI - Practical Deep Learning (long and detailed course with book)
- Community - Dive into Deep Learning
Books
… and of course there are some good old fashioned books…
- Python for data analysis - get started with numpy and pandas
- Data science from scratch - classical data science fundamentals
- Deep learning with python - neural networks using TensorFlow and Keras
- Hands on machine learning - classic machine learning (plus deep) with scikit
- 100 page machine learning book - overview of machine learning techniques
- Machine learning in Elixir - yes you can do ML in a language other than Python!
Papers
The ML community is a scientific, open, and sharing community, and almost all the key insights can be found in the scientific papers shared on arxiv.org. Due to the current excitement, new papers appear almost daily. Here are some of the ones I’ve found most insightful:
- Jul 2023 - Challenges and applications of LLMs
- Jul 2023 - LLaMA 2: Open foundation and fine tuned chat models
- Jun 2023 - A survey of LLMs
- Jun 2023 - BLOOM - A 176B parameter multilingual LLM
- May 2023 - Voyager - an open ended agent for LLMs
- May 2023 - Google - GQA - Grouped Query Attention
- May 2023 - QLoRA - UW - Efficient finetuning of quantized LLMs
- May 2023 - Google - Tree of Thought: Problem solving with LLMs
- May 2023 - Bloomberg GPT - An LLM for finance
- May 2023 - Tree of Thought - Problem solving with LLMs
- Apr 2023 - Harnessing the power of LLMs in practice
- Mar 2023 - A guide to Parameter efficient fine tuning
- Mar 2023 - Google - ReAct: reasoning and acting in LLMs
- Feb 2023 - LLaMa - Open and efficient foundation language models
- Jan 2023 - PAL - Program aided language models
- Jan 2023 - Google - Chain of thought prompting
- Jan 2023 - Google - LLMs are zero-shot reasoners
- Dec 2022 - Google - Scaling instruction finetuned LLMs
- Nov 2022 - Effectiveness of parameter efficient fine tuning
- Mar 2022 - Chinchilla - Training compute-optimal LLMs
- Mar 2022 - OpenAI - Training to follow instructions with human feedback
- Feb 2022 - OpenAI - Learning to summarize with human feedback
- Oct 2021 - Microsoft - LoRA: Low-Rank adaptation of LLMs
- Sep 2021 - Google - The power of scale for PEFT prompt tuning
- Apr 2021 - Facebook - Retrieval Augmented Generation (RAG)
- Jul 2020 - OpenAI - LLMs are few shot learners
- Feb 2020 - Fast AI - A layered API for deep learning
- Jan 2020 - OpenAI - Scaling Laws for neural language models
- Jan 2018 - UMLFit - language model fine tuning for text classification
- Dec 2017 - Transformers - Attention is all you need (2017)
Blog Articles
… and of course there are an infinite number of blog articles, but here are some of the ones I’ve found helpful:
- What we know about LLMs
- Large language models, explained with a minimum of math and jargon
- A complete guide to natural language processing
- How to use AI to do stuff
- Open source alternatives to ChatGPT
- How to build an LLM to answer questions about the Harry Potter universe
- How to implement Q&A against your documentation with GTP
- Summarizing Books
- An introduction to OpenAI function calling
- LangChain: The trendiest web framework of 2023 thanks to AI
- Using LLamaIndex to get GPT to turn a NL query into a (CLI) command
- Edgar: A voyager inspired software agent
- It’s starting to get strange - ChatGPT with Code Interpreter
- Llama 2: an incredible open source LLM
- Llama 2 is here
- Llama 2 on HuggingFace
- Introducing MPT-7B
- Star Coder: a state of the art LLM for code
- Using large language models with care
- Against LLM reductionism
- Emergent abilities of LLMs
- The illustrated transformer
- How to run LLMs locally
Conclusion
So, phew, that’s a wrap. This article ended up much longer than I expected, but it still really just scratches the surface of where we might be going with LLM development. There are many established and useful tools in the wider ML ecosystem, and the current focus on LLMs and NLP is exciting to see. Personally, I don’t really consider these techniques as “intelligence” as we might intuitively understand the term, and there is significant work required to make an LLM useful in a robust production environment… but they can be very powerful tools for understanding semantic language. As such they can be used - with the right training and orchestration - to open up new solutions to complex problems.
I think it’s going to be pretty exciting to see if these models can live up to their hype and become another tool in our developer toolbox.